Improve CI with Static Analysis
- 7 minutes read - 1470 wordsThis is the fifth in a series of articles about writing a small reading list app in Go for personal use.
A big part of developing quality software, especially in larger projects, is to make sure that your process, tools, and workflows can scale with the size of the project. The project we’re working on is tiny in the grand scheme of things, but let’s take this week to “sharpen the saw” a little bit and improve our process before diving back into functionality next week.
Earlier this week I shared some rules for semgrep, a static analyzer that we can use to find defects in Go web apps. Today we will integrate that into aklatan’s Makefile and CI pipeline.
At the end of this article you’ll:
- have semgrep with custom rules integrated into the CI pipeline
- understand the pros and cons of maintaining the rules alongside the application code (as opposed to keeping them in a separate repo)

A water pipeline in the Tagus-Segura Water Transfer in Spain. Photo by flicker user M.Peinado CC-BY
Adding semgrep to the Build
The goal: find problems in aklatan’s code using semgrep rules that we have written.
The way we drive everything else for this project is with the Makefile. So let’s add a rule to the Makefile to run semgrep on a local set of rules:
RULES := $(wildcard rules/*.yaml)
.PHONY: semgrep
semgrep: $(ALLGO) $(RULES)
semgrep --config rules/ --metrics=off
Now when we run make semgrep, it will run semgrep against config that we have in ./rules/ – so place copy all of the files (rules and test code) from the last article into that directory.
Make sure you’ve installed the semgrep cli properly, and have activated the python virtualenv. Now you should be able to run make semgrep … but it generates a bunch of findings from the test code! We can exclude those files by creating a file in the root of the project called .semgrepignore:
rules/
.venv/
This skips analysis of files in the rules directory and in the virtualenv where semgrep is installed. (You can skip the latter if you created a virtualenv in a different location.) When I run it now, I get a couple of screenfuls of output, ending with Ran 17 rules on 9 files: 4 findings.
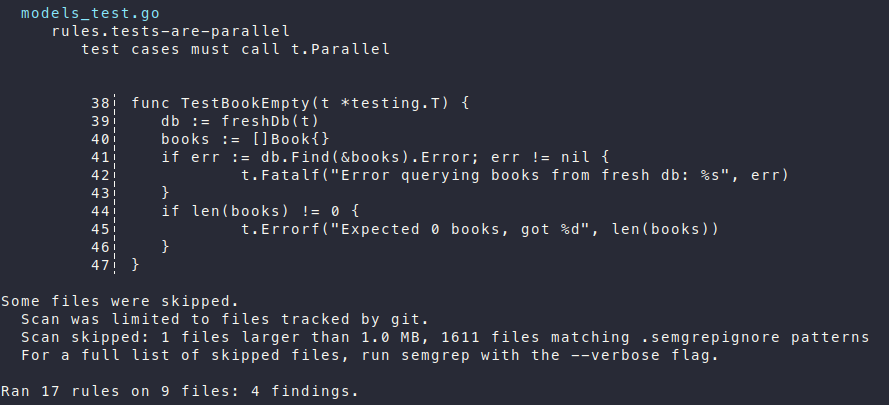
Screenshot of a portion of semgrep’s output, before fixing warnings.
Summary of the findings:
- I forgot to enable parallel testing for
TestBookEmpty. - None of the handlers conform to the naming scheme in the
handler-namingrule.
Note that I didn’t set any of these up as intentional errors in earlier posts to create examples for this post. I knew as I was wrapping up last week’s article about handling POST data that the naming was inconsistent, but I hadn’t yet written that rule.
These findings are simple to fix; I’m not going to show them here. Try fixing the issues yourself, and check my patch to see how your fixes compare to mine.
Unfortunately, adding the Go sample code to ./rules creates a few issues with the way the Makefile is invoking tools. This means that we can’t yet run make check to ensure that the fixes for the semgrep issues haven’t introduced some other defect.
First, golangci-lint is now reporting a bunch of issues with the sample code. Let’s fix that by adding --skip-dirs=rules:
.lint: $(ALLGO)
golangci-lint run --timeout=180s --skip-dirs=rules
@touch [email protected]
Next, go test is trying to build and test in the rules directory because it’s passing the ./... wildcard as the path. Since this project does not have any subpackages (yet) we can simply change these two command lines to use . instead:
./.coverage/$(PROJECT).out: $(ALLGO) $(ALLHTML) Makefile
go test $(TESTFLAGS) -coverprofile=./.coverage/$(PROJECT).out .
and
report.xml: $(ALLGO) Makefile
go test $(TESTFLAGS) -v . 2>&1 | go-junit-report > [email protected]
go tool cover -func .coverage/$(PROJECT).out
Tradeoffs
Before going further, it’s worth noting that this is not the only way to set up the semgrep integration. I’m biased towards local installation and against over-reliance on cloud services. (Yes, I use GitLab, but the workflows that I’ve been demonstrating are mostly independent of their service – if it disappeared tomorrow I can still get work done.)
Semgrep has a CI service that you can use. Returntocorp (the makers of semgrep) have a docker image and example GitLab config. Use it if you want. It has some benefits over the approach shown here – in particular I think the reporting of findings is easier to view. I don’t mind if my pipeline’s semgrep results are hard to parse because they should always be clean, since I primarily run semgrep during local development and the pipeline is just acting as a check on my process. The risk to be aware of is in adding a reliance on an outside service.
Another alternative approach that still preserves a local-first workflow is to put the rules into a separate repo, and configure the Makefile and CI to point to this repo when running semgrep. This approach could be very useful if you are going to use a common rule set across a number of projects. This is the approach that I’m going to use with my personal projects.
This series uses the fully-vendored approach for aklatan because it’s much simpler to explain and demonstrate.
For simplicity, I’m also not discussing the use of any rules from the central semgrep registry. That will probably come at a later date but I don’t have any concrete plans for that article yet.
Make it Work in the CI Pipeline
Now that semgrep is working locally it would be nice to have it run in our CI pipeline. This isn’t hard. We need to start with an image that has python, install semgrep, and then run it. Unfortunately semgrep has a dependency that requires gcc, so we have to apk add build-base in order to get that toolchain installed.
Here’s a confession, and a trick.
Confession: I almost always have to push multiple versions of .gitlab-ci.yml to get the pipeline to pass.
Trick: pull the docker image locally. Start a shell in a container, using a command line like docker run -v $(pwd):/mnt --rm -i -t --entrypoint /bin/sh python:3.10.4-alpine3.15. This mounts the current directory inside the container so that you can cd to /mnt to have access to your source tree. Run the commands you think you need to run for the pipeline to work. Add each command to the script: array in the pipeline yaml. Then when you’re done, exit the container, restart a fresh one, and paste each command in sequence from the script into the shell to make sure it works.
Using this trick can dramatically reduce the number of times you have to push changes to an MR to get the full pipeline working. (While writing this article, it saved me from having to make two extra pushes because I caught errors locally instead of in GitLab.)
Here’s the final version of the semgrep job in .gitlab-ci.yml:
semgrep:
stage: semgrep
image: python:3.10.4-alpine3.15
script:
- apk update
- apk add build-base
- pip install semgrep==0.86.5
- make semgrep
You will also need to add semgrep to the stages array at the top of the file.
Speeding it Up?
The whole pipeline runs for me in 2 minutes and 16 seconds:
Screenshot of the passing pipline.
That’s a pretty quick pipline. One strategy we could pursue to speed this up a little bit is to create a custom docker image with all the tools preinstalled, so that we don’t waste time downloading them during the pipline. This turns out to save much less time that you might expect. Even on GitLab’s free tier there is excellent network bandwidth so most tools install very quickly. This will likely only yield a time savings if you have lots of tools or if many things need to build themselves from source.
If you look at the merge request, the pile of commits I pushed to it, and the nearly two dozen pipelines I ran, you will see that pursuing this speedup is a dead-end, and it comes with a enough complexity that simply isn’t worth it for a project of this size.
When a project gets much bigger, and especially if there are many developers working on it, then it’s usually worth the complexity. But we’ll skip that for now and be happy with our simple pipeline that runs in just over two minutes.
Next Week
Next week I will cover form validation with Gin and we’ll improve the app’s error reporting.