How to Test Gin Web Handlers
- 14 minutes read - 2799 wordsThis is the third in a series of articles about writing a small reading list app in Go for personal use.
So far our app can show a page with a list of books that are in our database. It even has a unit test… but not a very good one. Today we’ll look at what it means to do a decent job testing a Gin handler function.
When we’re done you’ll have a test suite that thoroughly exercises the book list handler. You’ll have 100% test coverage of that handler, and you’ll also understand why that’s only a starting point.
Plus a free bonus that neatens up our CI pipeline.

A different kind of test.
Why isn’t the current test good?
It’s not bad, it’s just not testing very much. It is only going to catch (1) fundamental brokenness – failure of the app to even respond to the path or (2) if the template doesn’t contain the heading we expect.
It doesn’t add any books to the database, so it’s not even testing the most common case that users will exercise!
Errors it won’t detect:
- wrong behavior when there is a database error
- content errors when there are books in the database
- errors in the template code – for example, accessing the wrong field on a Book
Get Guidance from Coverage
If we look at the coverage report we can see which lines of the handler have not been executed by any tests. Load up .coverage/aklatan.html in your browser. You will see:
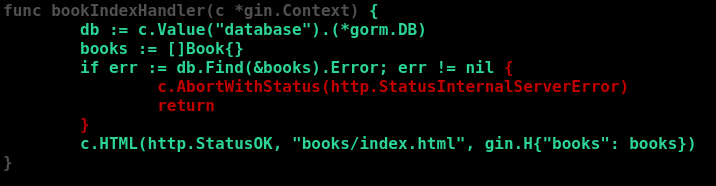
The lines in red never get run – because none of the tests exercise the database error path. In my experience the error paths are bugs tend to hide. They don’t get hit very often, and “correct” behavior when unexpected errors happen is usually either under-specified or completed unspecified.
For our app, we’ll specify a rule: if any error occurs in a handler, we will abort with a 500 error. (We’ll amend this when we get to validating user input.) Fortunately we’ve already got this rule coded in our handler.
Let’s write a test case that covers this path. How can we force a database read error? The first strategy I try is to have the test code drop the table that the handler is going to try to read from. This doesn’t always fit, but it works fine for our current case. We can use Gorm’s Migrator interface to perfrom the drop. (Note that DropTable returns an error not a DB, unlike most of the DB methods – so you don’t have to get .Error to check the status. This is an easy mistake to make.)
func TestBookIndexError(t *testing.T) {
t.Parallel()
db := freshDb(t)
if err := db.Migrator().DropTable(&Book{}); err != nil {
t.Fatalf("got error: %s", err)
}
_ = getHasStatus(t, db, "/books/", http.StatusInternalServerError)
}
We don’t need to verify any fragments on the response page, so we just assign the return value to _ to make it explicit that we’re intentionally ignoring this.
If you rerun make cover and reload the coverage html you will see that the function is now 100% covered. (The file won’t report 100% but all the lines in the file are green.)
The Lie That 100% Coverage Tells
This is great! 100% coverage means we’re done, right?
Let’s try injecting a bug into our template to see if any of the tests fail.
First, just remove the <li> line. This will make it so that no books will ever be listed. Save the template, run make – it reports success. That’s no good.
Next, restore the <li> line, but change it so that there’s a misspelled field: {{ .Titlex }}. Rerun the test and see that it still reports success.
Clearly our job is not done, for a few reasons.
First, getting to 100% coverage as reported by go tool cover only tells us that we’ve touched all of the source lines. The tool’s docs explicitly say:
For instance, it does not probe inside && and || expressions, and can be mildly confused by single statements with multiple function literals.
So we don’t have any indication if the tests fail to cover all the sides of these conditionals.
Second, it doesn’t even try to measure coverage of statements inside the templates. We saw this with the “typo” in the field name – there’s nothing in the reports to show that this template line doesn’t get exercised by the tests.
Third, coverage reporting has little to no correlation to how well the tests are validating output. We could write a test that probes all the boundaries of all the statements in the handler and the template, but if it doesn’t do any fragment checking then there could be all kinds of bugs in the output and we’d never know it.
This is not to say that coverage is useless. I find it very helpful for pointing out code that my tests have failed to exercise – especially error paths. But it’s important to be aware of the limitations of coverage reporting.
Testing Boundary Conditions
To more thoroughly test this handler we need to exercise all of the boundary conditions in both the function itself and in the template code.
These boundaries are:
- The error case from
db.Find. - Zero books are in the database.
- One book is in the database.
- Multiple books are in the database.
For this function and template, one vs. multiple books isn’t really a boundary case, but as a matter of habit I prefer to test both of these cases. Especially when I can make it trivial to add that extra test – this is shown in the final test case code below.
A Happy Path Test
The “happy path” through a function is the common, error-free case that is going to be hit most often.
On one hand, happy path tests are both important and useful: if this test fails it is because the function is broken in some fundamental way. They’re also useful for guiding refactoring.
On the other hand, happy path tests are mostly a waste of cpu cycles. This is because in practice they rarely detect a surprise failure – typically they only fail in an expected way while you’re refactoring. Also, all or most of the happy path is often redundantly exercised by other edge-case tests.
I tend to err on the side of overtesting, but I also try to be aware of how many other tests are going to cover the same paths. When possible I skip purely redundant test cases. This keeps test runtime lower and reduces the need for maintenance on useless test code.
Here’s a test for the nominal case – the case where there are books in the database, and they should appear on the page. (#4 in the list above.)
func TestBookIndexNominal(t *testing.T) {
t.Parallel()
db := freshDb(t)
b := Book{Title: "Book1", Author: "Author1"}
if err := db.Create(&b).Error; err != nil {
t.Fatalf("error creating book: %s", err)
}
b = Book{Title: "Book2", Author: "Author2"}
if err := db.Create(&b).Error; err != nil {
t.Fatalf("error creating book: %s", err)
}
w := httptest.NewRecorder()
ctx, r := gin.CreateTestContext(w)
setupRouter(r, db)
req, err := http.NewRequestWithContext(ctx, "GET", "/books/", nil)
if err != nil {
t.Errorf("got error: %s", err)
}
r.ServeHTTP(w, req)
if http.StatusOK != w.Code {
t.Fatalf("expected response code %d, got %d", http.StatusOK, w.Code)
}
body := w.Body.String()
fragments := []string{
"<h2>My Books</h2>",
"<li>Book1 -- Author1</li>",
"<li>Book2 -- Author2</li>",
}
for _, fragment := range fragments {
if !strings.Contains(body, fragment) {
t.Fatalf("expected body to contain '%s', got %s", fragment, body)
}
}
}
This is similar in structure to the original test but with two main differences:
- At the top we save the handle to our database in
db, and use it to create a couple of rows in the db. Row creation is very simple; we’ll cover this more in an upcoming post. - At the bottom we create a slice of strings that we expect to see in the page that is returned –
fragments. We then loop through the fragments, checking that each one is present in the page.
This test now ensures that our template is displaying a list of books correctly. But it has a lot of boilerplate that we’ll have to write for every test case. We can refactor some of this into helper functions:
- a function to create some number of books in the database
- a function to make a GET request and return the response
- a function to check that strings are in the response body
Helper Function: bodyHasFragments()
func bodyHasFragments(t *testing.T, body string, fragments []string) {
t.Helper()
for _, fragment := range fragments {
if !strings.Contains(body, fragment) {
t.Fatalf("expected body to contain '%s', got %s", fragment, body)
}
}
}
This just moves the loop at the bottom of the test function into its own function. There are a few things to note here:
- This is marked as a
t.Helper()– failures will be reported at the line number of the test case function instead of inside this function, which can make diagnosing a failing test easier. - Test helper functions should not return errors! Don’t create extra boilerplate in your tests with error handling. Helper functions should check errors and fail instead of passing errors up the stack.
- Both 1 and 2 are why every test helper function should take a
*testing.Tas the first argument. - I try to name my verification-type helper functions in the form
thingHasPropertyorthingIsStatus. I think this makes it easier to read what test code is checking.
Helper Function: getHasStatus()
You could quibble about the naming of this function: “get” is very common in programs and could be ambiguous. I think for test code in a web app that this has a reasonably obvious name in context. Especially since I anticipate adding a postHasStatus at some point in the future. If you don’t like the name, you can call it something different.
func getHasStatus(t *testing.T, db *gorm.DB, path string, status int) *httptest.ResponseRecorder {
t.Helper()
w := httptest.NewRecorder()
ctx, router := gin.CreateTestContext(w)
setupRouter(router, db)
req, err := http.NewRequestWithContext(ctx, "GET", path, nil)
if err != nil {
t.Errorf("got error: %s", err)
}
router.ServeHTTP(w, req)
if status != w.Code {
t.Errorf("expected response code %d, got %d", status, w.Code)
}
return w
}
This is just another straightforward extraction of duplicate code into a function.
Helper Function: createBooks()
func createBooks(t *testing.T, db *gorm.DB, count int) []*Book {
books := []*Book{}
t.Helper()
for i := 0; i < count; i++ {
b := &Book{
Title: fmt.Sprintf("Book%03d", i),
Author: fmt.Sprintf("Author%03d", i),
}
if err := db.Create(b).Error; err != nil {
t.Fatalf("error creating book: %s", err)
}
books = append(books, b)
}
return books
}
Previously we just created two hard-coded books. This extracts that code and transforms it into a loop so that we can create as many books as we want. It changes the naming scheme slightly, so we need to adjust the fragments we expect in our test function. Finally, it builds up a slice of the books so that it can pass them back to the caller – test cases can use this when verifying title/author in results.
Table-Driven Test Case
With those helper functions defined, we can refactor the nominal test case to this:
func TestBookIndexRefactored(t *testing.T) {
t.Parallel()
db := freshDb(t)
books := createBooks(t, db, 2)
w := getHasStatus(t, db, "/books/", http.StatusOK)
body := w.Body.String()
fragments := []string{
"<h2>My Books</h2>",
fmt.Sprintf("<li>%s -- %s</li>", books[0].Title, books[0].Author),
fmt.Sprintf("<li>%s -- %s</li>", books[1].Title, books[1].Author),
}
bodyHasFragments(t, body, fragments)
}
This is much more concise and easier to read than the previous version. However, I listed some other boundary conditions above – we should at least have test cases where there are zero and one books in the database. There’s already the “Empty” test case for zero books, but do we really need a whole separate function that is basically the “Refactored” test case just copy-pasted?
No: there’s a better way. We just need to create a table-driven test case that factors out the variable parts of the test, and then we can loop over the table.
This is what that looks like:
func TestBookIndexTable(t *testing.T) {
t.Parallel()
tcs := []struct {
name string
count int
}{
{"empty", 0},
{"single", 1},
{"multiple", 10},
}
for i := range tcs {
tc := &tcs[i]
t.Run(tc.name, func(t *testing.T) {
t.Parallel()
db := freshDb(t)
books := createBooks(t, db, tc.count)
w := getHasStatus(t, db, "/books/", http.StatusOK)
body := w.Body.String()
fragments := []string{
"<h2>My Books</h2>",
}
for _, book := range books {
fragments = append(fragments,
fmt.Sprintf("<li>%s -- %s</li>",
book.Title, book.Author))
}
bodyHasFragments(t, body, fragments)
})
}
}
At the top of the function, tcs (“test cases”) is a slice of an anonymous struct. The struct just contains the name of the test case and the number of books we want to insert before calling the handler.
In the body of the function there is a loop over that slice. For each test case we call t.Run which takes a test name and a function. It runs the function as a goroutine, and the subtest can be run in parallel (which ours is doing by calling t.Parallel).
NOTE: The initial version of this post used
for _, tc := range tcs, but there is a subtle bug here. I should know better by now, because this is not the first time I’ve been burned by this. (The bug doesn’t manifest in this test, but it will if you continue to apply the wrong pattern.)
The subtest function is just the main body of the “Refactored” test case, but we’ve moved the hard-coded book quantity into a member of the test case struct, and instead of hard-coding the fragments slice we loop over the books that are returned by createBooks to build up the fragments.
There is one more refactoring that we could apply to the test case table, but I won’t show it today. Let’s say that we wanted to move the “Error” test case into the table. If the struct had a setup func(*testing.T, *gorm.DB) member, then we could pass it the database, and drop the table in the setup function for the error case. The loop could skip calling setup if it was set to nil so that we don’t have to provide a setup function in every other test case. I’ll show an example of this strategy in a future post.
It’s worth noting that if you move too much stuff into the test case table the table entries can become complex to read and harder to understand. (I have occasionally taken this approach too far and have later had regrets when trying to decipher a failing test case!) As with everything else when coding, it’s a judgement call about how to manage the layers of abstraction.
Now that the tests are done, this feature is ready! We can commit our tests, push our branch to gitlab, and open a merge request. Review your changes, verify the pipeline passes, verify the coverage report shows an increased percentage, and merge it.
Screenshot of my open merge request just prior to merging.
Free Bonus: Unifying the CI Pipeline with our Makefile
To continue just a little bit with the theme of refactoring to remove duplication, let’s look at our CI Pipeline. Last week we added a Makefile to gather up all the steps to build, test, and generate reports, but we didn’t change the CI pipeline to use it. So if we modify something in the Makefile it won’t automatically be reflected in the pipeline. That’s easy to remedy.
Here’s an updated .gitlab-ci.yml that replaces several steps in the script with a single call to the Makefile. Note that we still have to install the depedencies – we’ll fix that in a future post with a custom docker image.
---
stages:
- build
build:
stage: build
image: golang:1.17.6-alpine3.15
script:
- apk update
- apk add build-base
- wget -O- -nv https://raw.githubusercontent.com/golangci/golangci-lint/master/install.sh | sh -s v1.43.0
- PATH=./bin/:$PATH
- go install github.com/jstemmer/[email protected]
- make all cover report.xml
artifacts:
when: always
reports:
junit: report.xml
Next: Users Can Add Books
Next Friday’s post will allow users to add books to their library. We’ll look at how Gin handles form input and how to test a POST handler.
Tuesday’s post is a look at what I’ve come to think of as a “Feedback Pyramid”
For the Friday Free Bonus we’ll look at one more way to tighten your feedback loop when running subtests. And a Special Surprise Bonus for email subscribers.