Web Accessibility Testing: Early & Often
- 7 minutes read - 1445 wordsAccessibility is Usability. If your app or site isn’t accessible, it isn’t usable – at least by some segment of the population. But also, if your app or site fails to meet accessibility criteria, it’s probably unusable by a larger segment of the population than you think. Just anecdotally I think that if an audit of your website shows a lot of accessibility-related defects, it’s rather likely that it’s crappy to use for fully-abled people too.
Let’s look at how we can build accessibility into our development process.
Like security, quality, and testability, accessibility (a/k/a “a11y”) isn’t something you can “bolt on” at the end of a development cycle. It needs at least a little bit of up-front planning so that we ensure we’re sticking to guidelines and don’t have to do a bunch of rework. And like those other “-ities”, if we pay attention to the guidelines they will actually help us avoid having an app that sucks – in more ways than just being unusable by people with disabilities.
If you’re clueless about accessibility, the W3C has a good introduction. I’m not going to talk about what it means or the technical requirements. I’m also not going to try to convince you it’s necessary any more than the sales pitch above. Click the link above the for the why and what. This article is about how to make it part of your day-to-day routine so that you can simply produce great software.
Where Does Accessibility Testing Belong?
As noted above, we should be thinking about accessibility from the beginning of the project. Part of this is just practical: if we wait until the end and discover that we’ve built an app with 50 pages and we use a scanner that comes up with 20 usability errors or warnings on every page, then we’ve got 1000 fixes to make! It’s like waiting to turn up the compiler warning level until the end of the project.
This means we should integrate some sort of accessibility testing into our feedback pyramid early in the life of the project. In the version of the pyramid I show in that article, a11y scan is in the middle of the pyramid as something that runs in CI – individual developers don’t have to run it on every compile.
CI-only is a reasonable choice. This ensures that developers can’t merge accessibility-related regressions in their MRs. But it doesn’t slow down their level 1/2 fast-feedback test reports.
What might be ideal is if there were a Go library that could take a web page (and linked CSS and whatever other resources are needed). Then we could write “unit tests” that fetched pages similar to some of our other tests and passed the page bodies into this validation library to check for violations. But I haven’t been able to find anything like this. (Please let me know if this exists!)
An interesting possibility is to write semgrep rules to warn on accessibility defects. I think it would be impossible to catch all categories, but these could at least catch some of the simpler structural warnings.
A hybrid approach is probably a good choice: add semgrep rules to catch the things that are easy to catch with that tool, especially if the accessibility scanner tends to catch certain violations a lot. Add unit tests for some things if there are patterns that are easy to catch that way, and you want to catch those things earlier rather than in an MR. And that have one or more accessibility scanners running in CI (and/or higher in the pyramid).
Testing Tools
There are tons of testing tools available. Unfortunately many of these are online services that want to do scans of a live website. This doesn’t really help us to remove errors during the development process, before a site is live.
There are also a number of audit services available, and while I think it’s very reasonable for a business to pay for an occasional outside accessibility audit, I’m mostly interested in making accessibility testing available to the masses so that (for example) open source projects are more usable by more people. Thus “Call for Pricing” automatically rejects a set of tools and services.
Another category of tools are intended to be run manually in the browser. This is better – at least we can run these on our local dev or staging apps and have a chance to fix problems before deployment. An example of this type of tool, and one that is especially low-impact to integrate is Khan Academy’s tota11y.
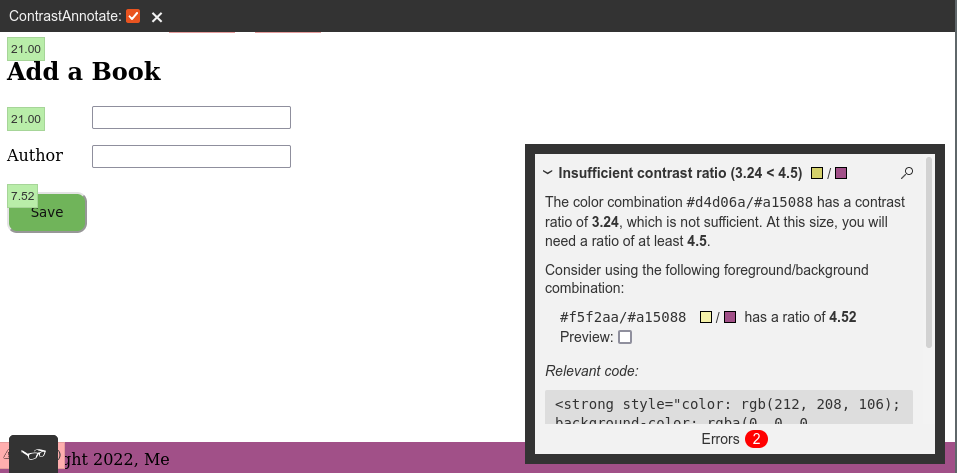
Screenshot of tota11y annotations in Aklatan.
This is great because it’s just a bookmarklet, and a couple of clicks gave me the information I need to fix the specific problems that were found. But I still find this to be a rather slow feedback loop, and it doesn’t fit well into a CI pipeline.
Two tools that I found that are specifically built for CI are bbc-a11y and pa11y-ci. The BBC tool specifically has a docker image that I’ve had good luck with so far. (I haven’t tried pa11y yet.) The examples below use bbc-a11y but should be adaptable to other tools.
It’s worth noting that I used bbc-a11y and tota11y on Aklatan, and they found a small number of errors that were not completely overlapping – so there is definitely value in using multiple tools for this testing.
Supporting Individual Developer Workflows
The encapsulation of bbc-a11y in a docker image makes it trivial to run the tool against a single url. Assuming you’ve got the app running in a separate terminal session, and it’s listening on port 3000 of your laptop, which has IP address 10.10.1.250:
docker run --rm --tty bbca11y/bbc-a11y-docker http://10.10.1.250:3000
This will generate a list of issues found in the main page of the app. Note that we use the external IP of the dev machine to keep things simple and avoid having to jump through any hoops with docker.
We can also pass a series of URLs on the command line and each will be checked in turn. Individual developers can check whatever url(s) they are actively working on to get fast feedback.
We can also maintain a config file with all of the urls in the app in bbc-a11y-config.js. One complication is that we need to do this in a way that allows each developer to customize the ip address where their app is running. We’ll do that by embedding an environment variable in the config file and then running a trivial bit of preprocessing. Here’s an example bbc-a11y-config.js:
page('http://$APP_PUBLIC_IP:3000/', {
})
page('http://$APP_PUBLIC_IP:3000/books/new', {
})
And we can process that with envsubst, which substitutes the values of environment variables in its input. And then we can mount the current directory as a volume in the docker container and tell bbc-a11y to use that config file:
% export APP_PUBLIC_IP=10.10.1.250
% envsubst < bbc-a11y-config.js > a11y.js
% docker run -v $(pwd):/mnt/ --rm --tty bbca11y/bbc-a11y-docker --config=/mnt/a11y.js
And then, because that’s just a little bit complicated to type all the time, we can add a Makefile rule that performs the substitution and runs the tool. Developers still have to make sure their app is already running, but mostly they can just run make a11y and the tests will run. And manual runs of single urls aren’t very complicated either.
a11y.js: bbc-a11y-config.js
@if [ -z "$$APP_PUBLIC_IP" ]; then echo "Must set APP_PUBLIC_IP"; exit 1; fi
envsubst < bbc-a11y-config.js > a11y.js
.PHONY: a11y
a11y: a11y.js
docker run -v $$(pwd):/mnt/ --rm --tty bbca11y/bbc-a11y-docker --config=/mnt/a11y.js
Integration with CI
Once you’ve got a Makefile rule that works locally, integrating with a CI pipeline is only a little bit of extra work. Different CI services will require slightly different approaches, but here’s a sketch of how it would work on GitLab’s CI:
- add a build step that creates a docker image with the app
- add an a11y job that:
- includes
servicesto run the app - sets the
APP_PUBLIC_IPto the “hostname” of the service - runs
make a11y
- includes
Upcoming
Later this week we’ll add a backend command to import data from CSV into Aklatan’s database.
A fully-worked example of the pipeline described above will be in a subscribers-only Special Bonus edition next week.
Next Friday we will dive into pagination (this will be really nice to have after importing a whole bunch of books with our handy importing tool).